Benchmarks
Test-Setup:
On all Systems a Fedora9-LiveCD was used, the xorg.conf file was edited manually.
945GM:
Core2Duo 2x2ghz, 3gb RAM, Intel 945GM IGP, Intel-2.3.2 driver
Driver provides quite good XRender accaleration.
Text was lcd-antialiased.
NV17/EXA:
Pentium-2.6ghz 100mhz fsb Northwood, 512mb RAM, NVidia GeForce 488Go 64mb, Nouveau 0.10
Driver works not as well as on 6600, no transformations, struggles a lot on lcd-antialiased text.
Text antialiasing was disabled.
NV17/XAA:
Same hw as with EXA, but with almost unaccalerated "nv" driver.
6600:
Sempron-3100+ 1.8ghz, 512mb RAM, NVidia GeForce6600 256mb, Nouveau 0.10
Works quite well. Fonts were rendered with grayscale antialiasing.
The X11 pipeline was not tested on 945GM/EXA, because performance is about 10x lower than on XAA.
Acceleration architectures:
XAA:
XAA is the old accaleration achritecture introduced with XFree86-4.
Not capable of accalerating XRender well, but allows shm pixmaps.
EXA:
EXA is the successor of XAA. It has a quite minimalistic design, focused mainly on XRender accaleration.
However its performance-wise not completly mature, however its getting better every Xorg release.
1. Swing Benchmarks:
1.1 MigLayout Benchmark / Ocean:
This benchmark is one of my favourite Swing benchmarks. It in my opinion reflects very well how "responsive" the application will "feel".
Unfourtunatly it does not play nice with Nimbus (really a lot of cycles are spent in Nimbus cache-lookup routines), so this test was only ran with the Ocean LookAndFeel:
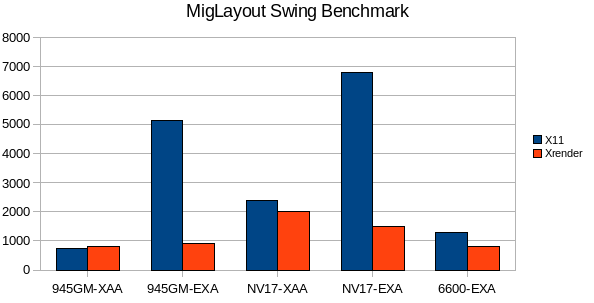
Numbers are execution time for one round in ms, lower is better.
The XRender pipeline does quite well for this test keeping in mind that almost everything except antialiased text is accalerated by the X11 pipeline too.
The same text antialiasing options have been choosen for one hardware type on both pipelines, so X11 and XR can be compared only on the same hardware.
It looks a bit odd that the XRender pipeline is faster on XAA than on EXA, although the former is mostly unaccalerated.
The image shows a profile of the X-Server done with sysprof:
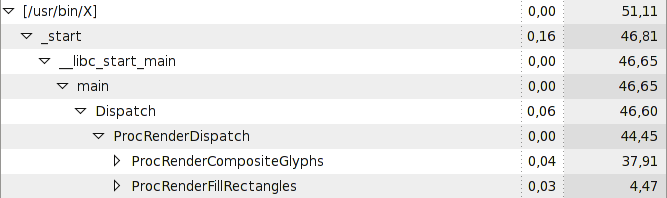
So, 51% of total time is spent inside Xorg, only 28% in the Java process (not shown here).
44% of those 51% are consumed by XRender commands, almost ~38% by text rendering and ~5% by rectangles.
Although inside of CompositeGlpyhs a lot of migration happens (because of the non-accalerated Gradients I guess) a lot of time is spent compositing the glyphs.
As mentioned here, theres a lot of work ongoing to improve text-performance with EXA - which will directly reflect in the swing benchmark results.
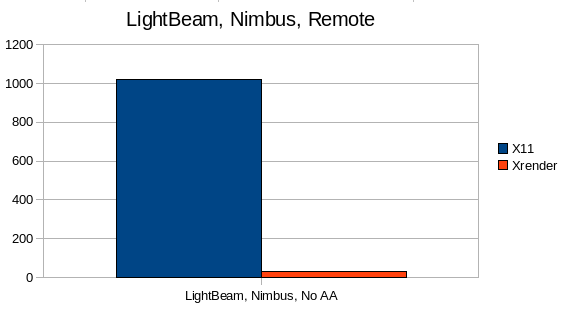
1.2 LightBeam / Nimbus:
Nimbus was tested with the LightBeam benchmark, originally developed to benchmark the Substance LookAndFeel:
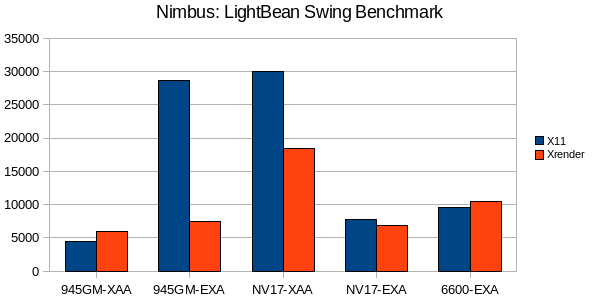
Numbers are execution time for one
round in ms, lower is better.
For Nimbus the new pipeline doesn't work that well. It offers a great speedup for drivers that don't allow shared memory pixmaps (945-GM-EXA or over network), but other than that its sometimes faster, sometimes slower than X11.
Nimbus does a lot MaskFills/MaskBlits where the X11 pipeline has an advantage with its shared pixmaps, furthermore transformed blits are used a lot which are implemented a bit suboptimal.
I plan several enhancements for transformed as well as MaskFills/Blits blits which should speed up Nimbus quite a lot.
2. Java2D over Network:
The same swing benchmarks executed over network:
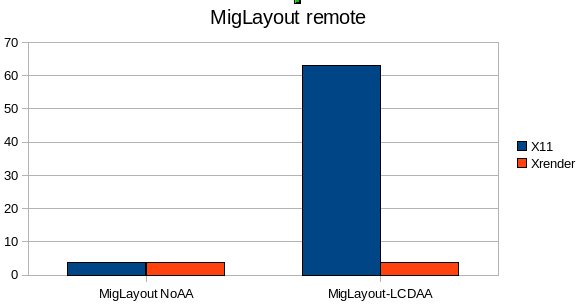
Time in seconds, lower is better
For the MigLayout benchmark XRender benefits a lot because it supports antialiased font rendering without readbacks. Without font antialiasing both pipelines produce almost the same results, but if font aa is enabled the X11 pipeline starts to fall back.
Nimbus score is way better (factor 33x) because it uses shape-antialiasing, as well as transformed images a lot.
The XRender pipeline just sends the appropriate commands or mask-images to the X-Server, whereas the X11 pipeline has to read back image contents from the Server, modify it and upload it again which means a full round trip.
For the nimbus-test ~250mb data had to been moved arround over wlan when running on the X11 pipeline.
Both Computers were conneted over 11mbit/s wlan running at ~5mbit/s with about 3ms roundtrip latency - to simulate something between fast LANs and fast Internet connections (also 1-16mbit but higher latency).
The X-Server was running 945-GM-EXA.
3. Syntehtic tests:
The synthetic tests were done using J2DBench, results (except text) are pixels/s - higher is better.
J2DBench is a great tool for optimizing the performance of a single primitive, but it often does not reflect real-world performance.
J2DBench's behaviour for example never triggers excessive pixmap migration which can hurt quite a lot.
1.1 Solid Fills:
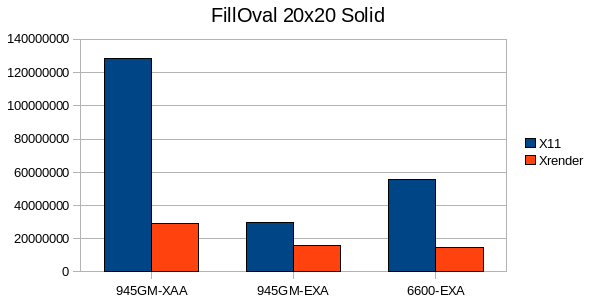
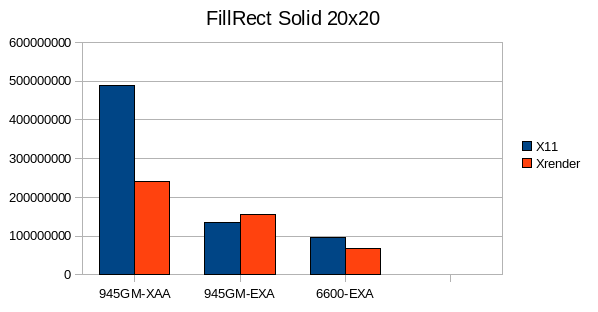
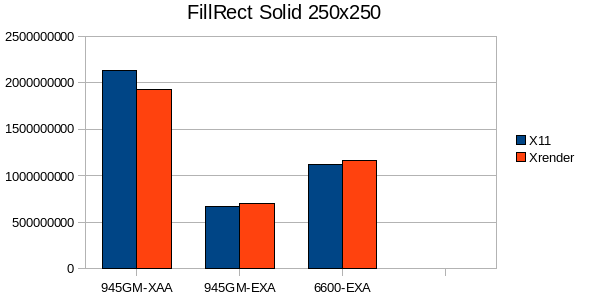
XRender has a disadvantage in FillOval because it has to send spans to the X-Server, whereas the X11 pipeline can use XArcs.
For the 20x20 rect case my pipeline seems to have a high per-primitive overhead.
However overall FillRect performance is a bit disappointing with EXA enabled, most time is spent in Xorg, but according to sysprof no fallback is hit - I'll write some stand-alone testcases to analyze the performance further.
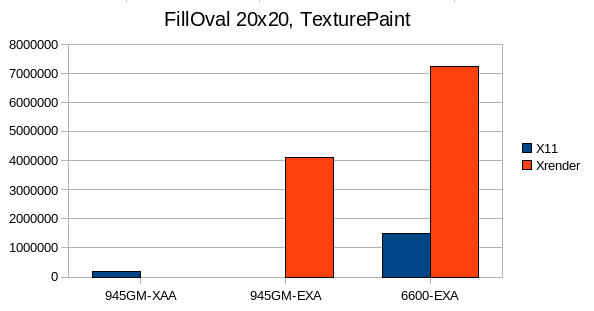
TexturPaint is one area where XRender is really shines, no matter for which geometry.
1.2.1 Antialiased Shapes:
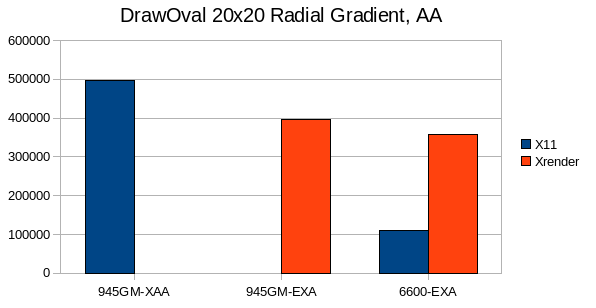
The gradient case is interesting because there is currently no driver which is able to accalerate gradients, also lines are not accalerated on EXA and some workarrounds are used to not cause pixmap migration.
With EXA beeing almost on par with XAA, which allows direct pixmap access, these results are quite good.
Hopefully at least 2-way gradients will be accalerated by EXA soon.
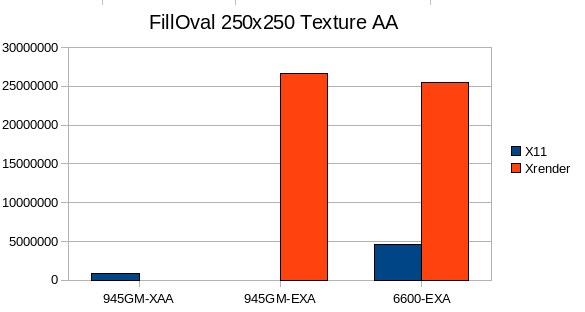
Again TexturePaint, but this time with antialiasing. I've no idea why the 945GM does that bad with XAA, also the 6600 is probably hit by hardware-setup-overhead, mask batching could quite help here.
1.3 Image benchmarks:
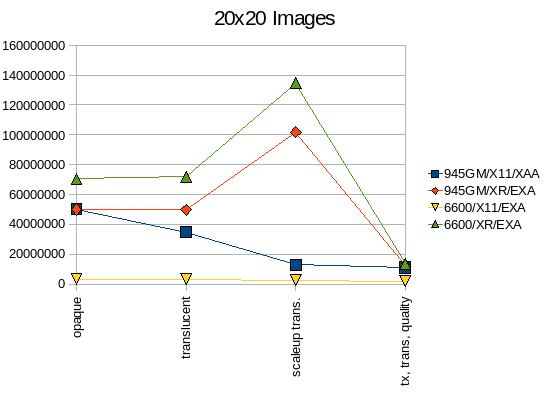
For 20x20 Images the XRender pipeline works quite well, however for small transformed images there is for now still too much overhead, however I am already working on an improvement - which should result in somewhere between 2.5-5E7 pixels/s.
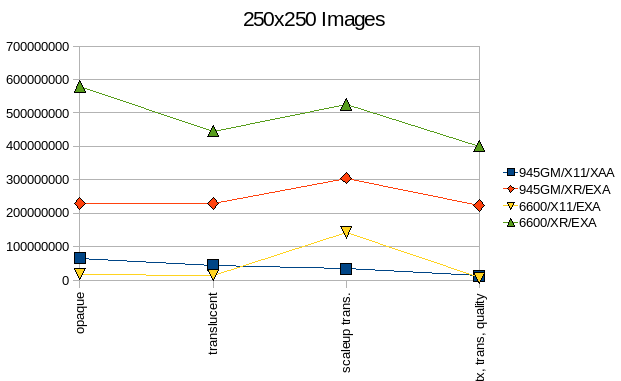
The 6600 with its dedicated VRAM is clearly faster than the 945-IGP, setup-costs are not dominant anymore.
1.4 Antialiased Text:
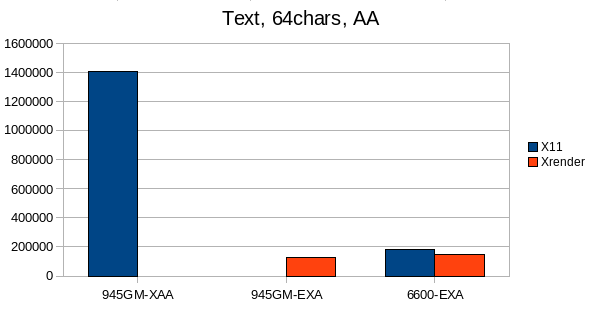
Text is currently a weak point of EXA, but theres a lot of work ongoing to fix that issue, however in real-world software difference is quite likely not that large.
The improvements mentioned here are already in master, and should lead to a great improvement in text performance.
Intel hired the current cairo-maintainer Carl Worth to work on performance improvements specific to the Intel-Driver, so both driver focused and general improvements should be available soon.
4. Benchmark Conclusion:
In many cases the X11 pipeline can be very efficient if it has direct access to image data using the shm pixmap extension, however as the swing-benchmarks show, often the advantage is not as large for real-world workload.
XRender accaleration is currently evolving fast. There are still a number of performance bugs in Xorg-server-1.5/EXA that prevent it exceling performance-wise, but performance is already quite ok and xserver-master shows that things are improving steadily.
Most likely with release 2.5 Intel will introduce support for direct vram-access with GEM, which should give many operations a real boost, especially in the case of driver-fallbacks and hopefully other drivers will introduce support for it soon.
NVidia announced that a future driver release comming soon will accalerate many operations currently not supported by their proprietary drivers, once its released I will adapt the benchmarks of course (and I expect great speedups).
RadeonHD will soon accalerate EXA on AMD's R5xx and R6xx chips.
Furthermore there are still many opportunities to also tune the XRender pipeline.